Picking up Soft 3D Objects
Translation: Polish | Hungarian
The human hand is experienced at manipulating soft objects in the daily life. For instance, to pick up such an object from a table, the hand usually squeezes it first with two or more fingers to achieve a firm grip. The squeeze is sometimes downward (against the table) in order to leverage the table's support to stabilize the object during the action and generate large enough contact regions to for the needed friction. While squeezing the object, the fingertips in contact are feeling its weight as well as the firmness of the grip to decide when to lift it. Once a lift starts, the hand may apply some extra squeeze to prevent any possible slip.
Inspired by the squeeze-and-lift behavior, we introduce a strategy for a robotic hand to pick up deformable 3D objects at rest on a plane, using two rigid fingers with no force or tactile sensing capability. Initially two fingers are placed at two locations on the object that would achieve “force closure” with the table contact if the object were rigid. The fingertips then begin to squeeze the object slightly downward against the table. The growing contact areas further constrain the object from any rotation or translation. After every extra amount of squeeze, a virtual liftability test is performed to estimate the progress in the form of “what portion of the object’s weight can be lifted up”. Once the test is passed, both fingers switch to upward translations to lift the object off the table.
Grasping deformable 3D objects differs from the 2D version of the task in several aspects beyond just the addition of one dimension. Gravity can no longer be ignored given the volume of a 3D object. First, it affects the object’s deformation even in the absence of any external load. Second, gravity needs to be eventually balanced by the finger forces alone in order to lift the object off the supporting plane. Third, gravity is mainly responsible for causing contact slips between the object and the fingertips during such a lift.
Like our previous handling of the 2D grasping task before, we will sequence the entire squeeze-and-lift operation into periods within each of which the contact configuration under a finite element discretization does not change. During a single period, the displacements of the contact nodes are either known or estimable from the finger movements. From them we hope to determine the object’s deformation, which in turn causes new change in the contact configuration to begin the next period.
Under linear elasticity, any displacement field that yields zero strain energy is linearly spanned by three fields representing translations and three more representing rotations. Based on this, we first perform the finite element analysis (FEA) to obtain the deformed shape of a solid from specified contact displacements, under gravity. The solution is unique as long as the contact points are not collinear. To track the (changing) contact configuration, we repeatedly solve for the extra deformation based on the current contact configuration and stepwise finger movements.
1. Liftability Test
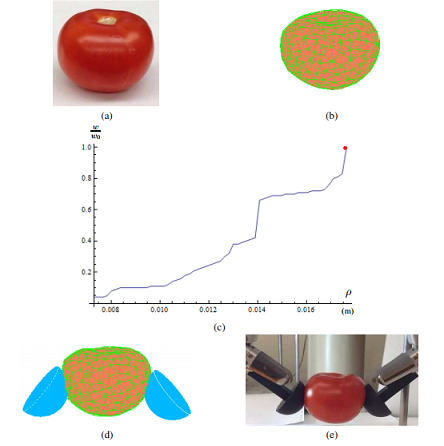 When the squeeze depth is small, the contact regions between the fingertips and the object are small and unable to create enough friction to hold the object if it is to be picked up. As squeeze depth increases, the fingertips may stop squeezing at the moment they “feel” that the object is liftable. To check on such “feeling”, We conduct a virtual liftability test repeatedly as squeeze depth increases. Such a test, involving no physical action, predicts the finger contact forces at the current depth if the support plane were to be removed, and then checks if one of the fingertips would be slipping as a result.
When the squeeze depth is small, the contact regions between the fingertips and the object are small and unable to create enough friction to hold the object if it is to be picked up. As squeeze depth increases, the fingertips may stop squeezing at the moment they “feel” that the object is liftable. To check on such “feeling”, We conduct a virtual liftability test repeatedly as squeeze depth increases. Such a test, involving no physical action, predicts the finger contact forces at the current depth if the support plane were to be removed, and then checks if one of the fingertips would be slipping as a result.
We introduce the notion of ‘liftable weight’. At a squeeze depth, the liftable weight is the maximum (hypothetical) weight of the object that would not result in any fingertip sliding if support plane were removed. The harder the two fingertips squeeze, the more weight they tend to be able to lift. Generally, we expect liftable weight to be also monotonically increasing. The idea is then to track liftable weight as squeeze depth increases until it equals the original weight of the object. Once liftable weight reaches or exceeds the actual weight of the object, the liftability test is passed.
The right figure shows a tomato (see (a) and (b)) grasped by two hemispherical plastic fingertips mounted on the fingers of a Barrett Hand (see (d) and (e)). As we can see, the ratio (liftable weight)/(original weight) increases monotonically with the squeeze depth. The object becomes liftable when squeeze depth is equal to 0.0176. The moment is shown in (d) with seven contact nodes on each finger and five in the plane. The object is lifted off the plane (shown in (e)) immediately afterward.
2. Squeezing and Lifting
The fingers begin to squeeze the object under their specified translations. The contacts of the object with the fingers and the plane grow. The squeeze continues until either at some instant the liftability test is passed, or the amount of squeeze becomes too large that the object is deemed impossible to pick up under the initial finger placement and squeezing directions.
Translations of the fingers are sequenced by contact events. There are four such events: contact establishment (A), contact break (B), stick-to-slip (C), and slip-to-stick (D). Event A is detected when a node is to penetrate into a fingertip or the plane. Event B happens when the contact force at a node is pointing outward from the object. Event C takes place when the contact force at a node is out of its friction cone. Event D occurs when the the sliding distance of some node stops changing.
Between two events, the movements of all sliding nodes need to be tracked. A node is sliding if the calculated contact force is out of the friction cone. In this case, its sliding direction is opposite to that of the tangential component of the contact force. On a fingertip, a node slides on a great circle within the period corresponding to one increment in the squeeze depth. With sliding directions determined, the contact forces are linear in the sliding distances of all such nodes. Coulomb’s friction law then induces a system of equations, which can be turned into a system of quadratic equations solvable using the homotopy continuation method.
When the liftability test is passed, the fingertips lift the object in an upward translation. During the lift, the nodal contacts with the plane will break one by one, and some contacts with the fintertips could also break under the gravitational force. Modelingis is no different from that of squeezing, however. If all nodes on one finger are sliding, the object slides on the finger the pickup fails. Otherwise, the operation is a success when the object breaks contact with the plane
To validate the pickup algorithm, we experimented over five deformable objects including the tomato shown in the above and four other objects: an orange, an eggplant, a steamed bun, and a toy football, all shown in the left table below in their resting configurations and in tetrahedral meshes. When the liftable weight exceeded the weight of the object, the fingers immediately switched the action from squeezing to lifting. The first row of the right table below shows the four objects picked up by the Barrett Hand at the squeeze depths 0.0124, 0.0071, 0.0052, and 0.0053, respectively.11 The second row shows the corresponding simulation results.


For more information, we refer to the following papers:
Huan Lin, Feng Guo, Feifei Wang, and Yan-Bin Jia. Picking up a soft 3D object by “feeling” the grip [ Abstract ] (572K, 40 pages). Accepted to International Journal of Robotics Research, 2014.
Huan Lin, Feng Guo, Feifei Wang and Yan-Bin Jia. Picking up soft 3D objects with two fingers (1049 K). In Proceedings of the IEEE International Conference on Robotics and Automation , pp. 3656-3661, Hong Kong, China, May 31 – Jun 5, 2014.
 This material is based upon work supported by the National Science Foundation under Grant IIS-0915876.
This material is based upon work supported by the National Science Foundation under Grant IIS-0915876.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Last updated on Sep 8, 2014.